import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.formula.api import ols第8章のPythonコード
第8章 ランダム化実験
モジュールのインポート
8.1 授業の出席率と成績:セレクションバイアス
8.1.1 因果関係?単なる相関関係?
classdata = pd.read_csv('class_attendance.csv') # データの読み込み
sns.set_theme()
sns.stripplot(x = 'D', y = 'Y', data = classdata)
plt.show()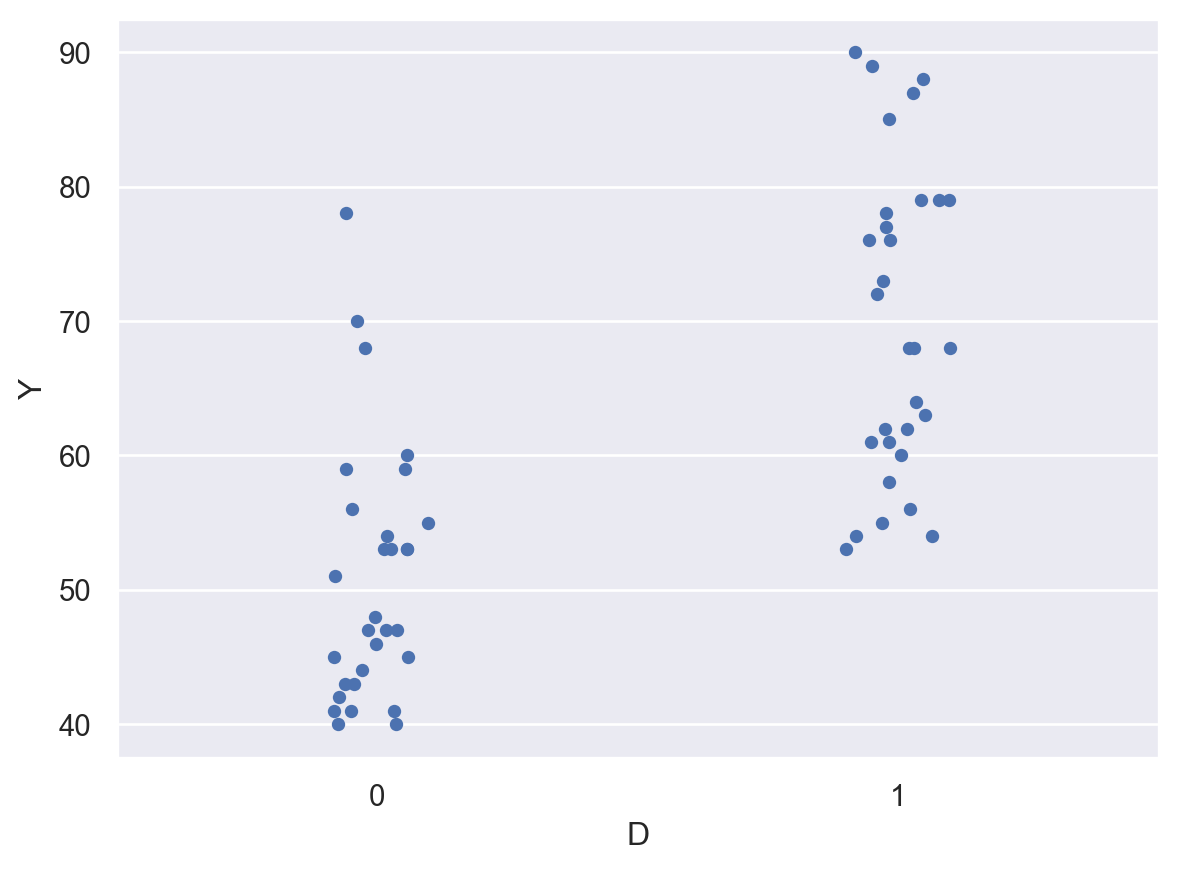
8.2 ランダム化実験
8.2.2 セレクションバイアスの除去
result = ols('Y ~ D', data = classdata).fit()
result.paramsIntercept 50.733333
D 19.100000
dtype: float64Y1mean = sum(classdata.eval('D * Y')) / sum(classdata['D'])
Y0mean = sum(classdata.eval('(1 - D) * Y')) / sum(1 - classdata['D'])
Y0mean # コントロールグループの平均値 = α
Y1mean - Y0mean # 平均値の差 = β19.099999999999994meandata = classdata[['D', 'Y']].groupby('D').mean().transpose()
meandata.assign(diff = meandata[1] - meandata[0])| D | 0 | 1 | diff |
|---|---|---|---|
| Y | 50.733333 | 69.833333 | 19.1 |
result = ols('Y ~ D + motiv', data = classdata).fit()
print(result.summary().tables[1])==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 41.2033 2.801 14.712 0.000 35.595 46.811
D 1.2385 4.817 0.257 0.798 -8.407 10.884
motiv 0.9888 0.231 4.276 0.000 0.526 1.452
==============================================================================